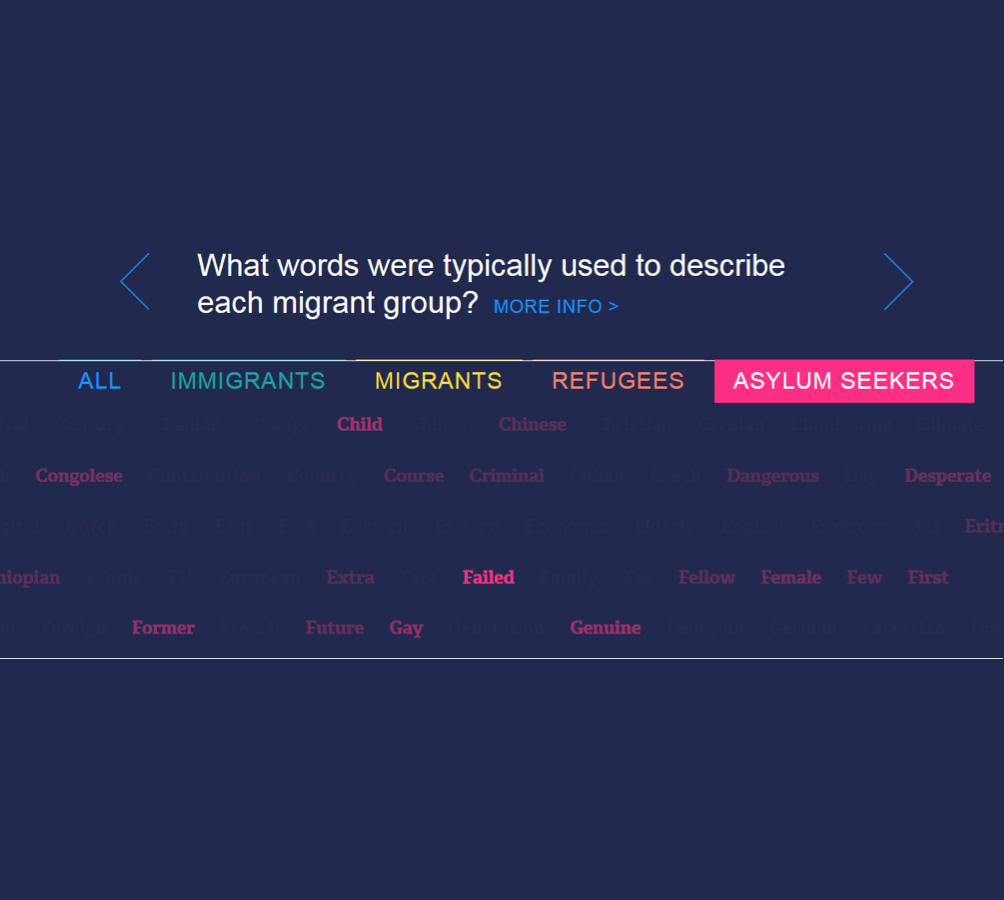
Researchers using corpora can visualise their data and analyses using a growing number of tools. Visualisations are especially valuable in environments where researchers communicate and work with public-facing partners under the auspices of ‘knowledge exchange’ or ‘impact’, and corpus data are more available thanks to digital methods. However, although the field of corpus linguistics continues to generate its own range of techniques, it largely remains orientated towards finding ways for academics to communicate results directly with other academics rather than with or through groups outside universities. Also, there is a lack of discussion about how communication, motivations and values also feature in the process of making corpus data visible. My argument is that these sociocultural and practical factors also influence visualisation outputs alongside technical aspects. I draw upon two corpus-based projects about press portrayal of migrants, conducted by an intermediary organisation that links university researchers with users outside academia. Analysing these projects' visualisation outputs in their organisational and communication contexts produces key lessons for researchers wanting to visualise text; consider the aims and values of partners; develop communication strategies that acknowledge different areas of expertise; and link visualisation choices with wider project objectives.
Citation
Allen, W. (2017) Making Corpus Data Visible: Visualising Text With Research Intermediaries, Corpora, 12(3): 459-482 [OPEN ACCESS]